My three year old knows to say “sharing is caring” when his older brother is playing with a toy he wants. Sometimes it works, often it doesn’t; thankfully, sharing threat intelligence data works differently. Once the mechanism for sharing is established, it’s essentially free to share, and no one has to give up their “toy”. But do we want to “play” with other people’s “toys” when it comes to threat intelligence? </tortured_analogy> 🙂
One of the big questions people have for me on threat intelligence sharing is whether it provides value. Our own experiences here at Duke say that it does, and the limited cases where we’ve found other higher education institutions sharing their own data, we’ve found the data to be highly applicable to our own networks, with the caveats that the data is shared as close to real-time as possible, and protections are applied in an automated fashion. The key to getting value from many sources of threat intelligence data is the velocity of the data from source into protection devices.
A primary hypothesis for the STINGAR project is that if higher education networks collect information about attacks against their networks using honeypots, share that data as quickly as possible with other higher education participants, and automatically block on this data, attacks will be less effective overall. We recently received data from one of our partners which seems to back our hypothesis.
This partner has been running CHN in their environment for several months now, and decided in early December to start putting their own data into their border firewall for automatic blocking. Recently, they also decided to incorporate the data available via the shared CIF repository into their blocking rule.
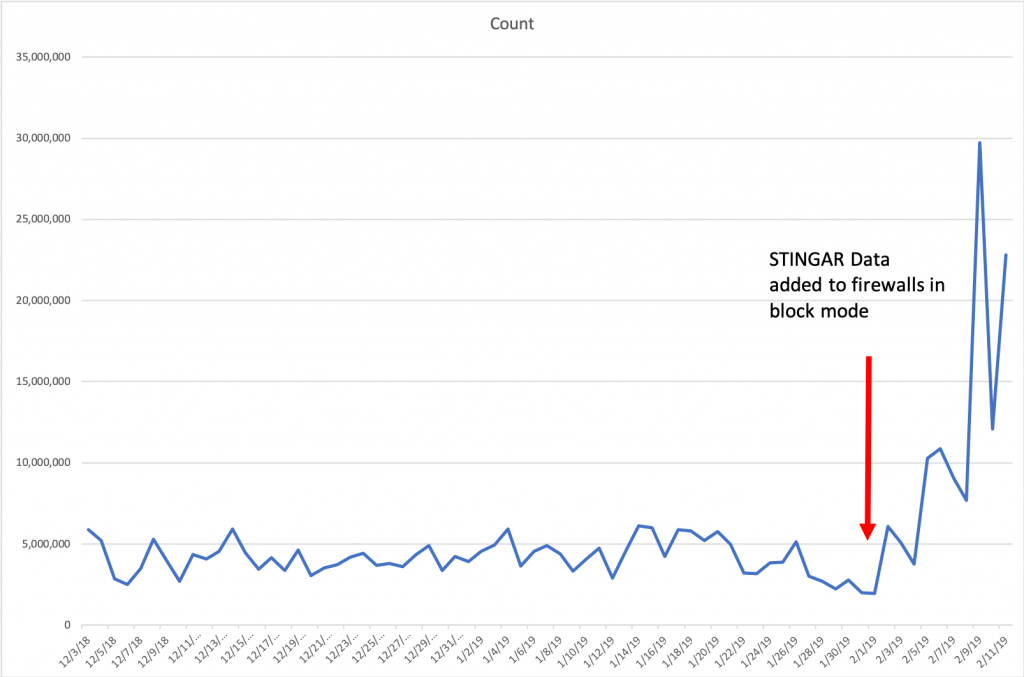
Please note: The “Count” is connections blocked per day.
So after averaging 4.1 millions connections per day blocked, inclusion of the STINGAR data pushed this average up to 11.7 million connections per day blocked, a near three-fold increase. I’m personally very excited to see this data. While we cannot know the intent of those connections, we do know that there haven’t been any reported false positives to the partner based on the blocking they’ve done. I think this is another data point (outside our own experiences) that points to high-speed sharing of data with automated blocking as a valuable tool in the network defense toolbox.
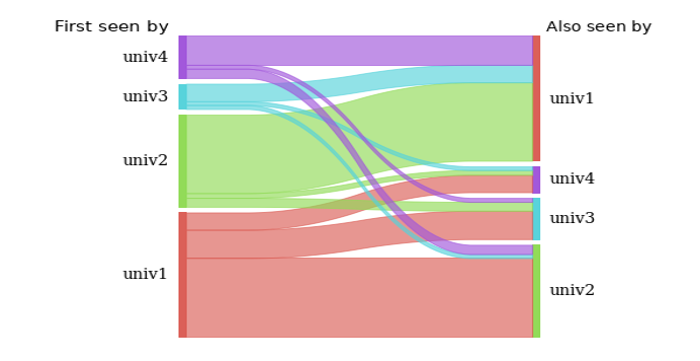
Looking for IP’s that get detected by more than one institution is another way to start to measure applicability of the data between institutions. While the number of institutions actively sharing data is still on the lower end of the scale we eventually anticipate, we’re starting to see a decent amount of IP overlap between institutional sensors.
I’d love to hear your thoughts on the matter! If you’re a higher education institution you’re welcome to join our mailing list stingar@duke.edu to share your thoughts in a closed forum, or otherwise feel free to join us at Github (file an issue, or join us on Gitter).
Cheers,
Jesse